Proc1C10N: AI-Optimized FPGA Accelerator with HBM2 Technology
The Proc1C10N™ is a compact, ultra-high-performance FPGA accelerator built on Altera Stratix® 10 NX FPGA. Designed for AI-driven, compute-intensive, and high-bandwidth applications, it not only integrates embedded Tensor blocks with HBM2 memory but also delivers 143 INT8 TOPS / FP16 TFLOPS of processing power. As a result, this FPGA accelerator provides exceptional throughput and efficiency for advanced AI workloads.
AI Performance and Memory
This AI-focused compute accelerator combines 16 × 25 Gb/s full-duplex transceivers with a robust multi-level memory architecture. Additionally, it features embedded MLABs and M20K, tightly coupled HBM2 and eSRAM, and supports up to 128 GB DDR4. Therefore, the Proc1C10N achieves ultra-low latency and high bandwidth, making it ideal for AI acceleration, HPC, networking, and edge-compute environments.
Connectivity and Expansion Options
The half-length PCIe Gen3 x16 board includes 4 × QSFP28 ports, a Gidel PHS connector for daughterboards, and 19 GPIOs for peripheral control. Furthermore, the PHS enables up to 128 Gb/s Rx/Tx, ensuring seamless integration with 8× CoaXPress-12 cameras via a Gidel CXP daughterboard. Consequently, the Proc1C10N is well-suited for real-time vision and edge AI applications.
Development Tools
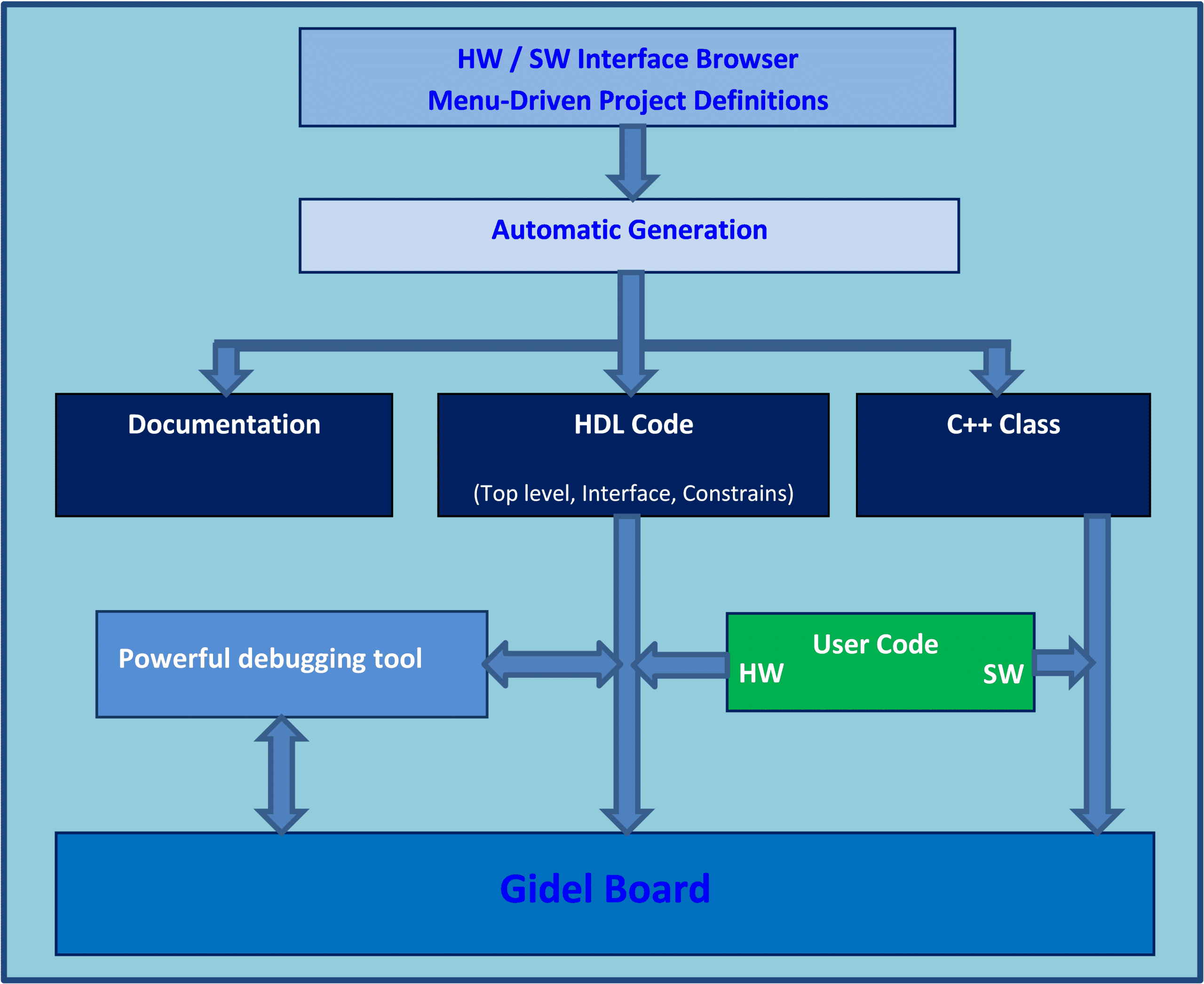
Supported by Gidel’s advanced development suite, the Proc1C10N FPGA accelerator streamlines integration and shortens development cycles. Moreover, it supports C and HDL-based design, reducing engineering effort, enhancing reliability, and accelerating time-to-market.
Why Choose the Proc1C10N FPGA Accelerator?
-
Embedded Tensor blocks for optimized AI performance
-
HBM2 memory for 10X more DRAM and SRAM bandwidth
-
143 INT8 TOPS / FP16 TFLOPS for high-demand AI workloads
-
Compact PCIe design for versatile system integration
For more accelerator card options, visit FPGA Compute Acceleration – Gidel